Fiziksel Veri Tabanı Modellemesi
Fiziksel Veri Tabanına Giriş
VTYS bilgileri ikincil hafıza olarak da adlandırdığımız yan bellekte (hard diskte) tutar.
VTYS’nin verileri yan bellekte tutmasının bazı sonuçları vardır. Bunlar;
•READ: Verilerin yan bellekten (hard disk) ana belleğe (RAM) transfer edilmesi.
•WRITE: Verilerin ana bellekten yan belleğe transfer edilmesi .
•Bu iki operasyon oldukça pahalıdır. Bundan dolayı çok iyi planlanmalıdır.
•Bu durumda neden tüm veriler ana bellekte tutulmuyor diye sorulabilir. Bunun nedenlerini şöyle sıralayabiliriz:
–Ana bellekte veri tutmanın maliyeti çok fazladır.
–Ana bellek geçicidir(volatile). Verileri yürütmeler esnasında kaybetmek istemeyiz.
Tipik depolama hiyerarşisi şu şekildedir:
•RAM halihazırda kullanılan veriler içindir. (ana bellek)
•Disk ana veritabanı içindir. (ikincil bellek)
•Teypler verilerin eski versiyonlarını tutmak içindir. (üçüncül bellek)
•Disklerde veriler disk blokları ya da sayfalar halinde tutulur ve alınırlar.
•Ana bellekten farklı olarak bir disk sayfasını alıp getirmenin maliyeti o sayfanın diskteki yerine bağlıdır. Dolayısıyla sayfaların diskte relatif yerleştirildiği yerler VTYS’nin performansına en fazla etki eden faktördür.
Disk sayfasına erişim zamanı
Bir disk sayfasına ulaşmanın (READ ve WRITE) zamanı üç değişik zamanın toplamıyla bulunur.
•Arama zamanı (seek time – disk kolunun hareketi için gerekli zaman)
•Dönme zamanı (rotational time – disk blokunun disk başının altına gelmesi için gerekli zaman)
•Transfer zamanı (transfer time – verinin disk yüzeyine/yüzeyinden hareketi için gerekli zaman)
•Arama ve dönme için geçen süre tüm süreyi en fazla etkileyen süredir. Örneğin arama zamanı 1 ile 20 msec arasında değişirken, dönme süresi 0 ile 10 msec ve transfer süresi her 4 KB sayfa için 1 msec’dir. Bu süreler teknolojinin gelişmesiyle değişmektedir, ancak göreli hız farklılıkları hala benzerdir.
•Bu durumda I/O masrafını azaltmanın anahtarı arama/dönme gecikme sürelerini azaltmaktır.
Sayfaları yerleştirme
Diskte sayfaları yerleştirme biçimi I/O masrafını azaltmakta etkili olabilmektedir. Örneğin bir sonraki bloğun aynı iz(track) üzerinde olması, bir kütükteki blokların ardarda yerleştirilmesi arama ve dönme gecikmesini en aza indirir.
Buna ilave olarak eğer bir ardısıra (sequential) bakma yöntemi kullanılıyorsa, bir anda birkaç sayfanın önceden alınması masrafın azaltılmasında etkili olur.
VTYS’nin en alt seviyede yönettiği diskteki alanlardır. Daha yukarıdaki seviyelerdeki çağırma
–sayfayı tahsis etmek/geri tahsis etmek (allocate/deallocate)
–sayfayı oku/yaz
Yüksek seviyelerde sayfaların tahsis istekleri belirtilir ve bunun nasıl yapıldığının, boş alanların nasıl yönetildiğinin bilinmesine gerek yoktur.
Buffer kullanımı
Bir VTYS’de ara bölge (ya da tampon - buffer) yönetimi veri tabanının performansını artıran bir yaklaşımdır.
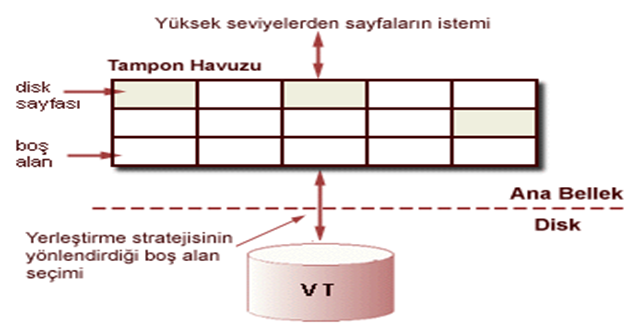
Popüler yerleştirme stratejilerinden;
–en az son zamanlarda kullanılan (least recently used, LRU)
–en son kullanılan (most recently used, MRU)
günümüzde kullanılan en önemli yerleştirme stratejileridir.
Fiziksel Veri Tabanı Tasarımı
•Fiziksel veri tabanı tasarımı veri tabanının etkin bir şekilde işlenebilmesini sağlayan belirli bir veri organizasyon tekniğini seçmeye dayanır.
•Birbiriyle ilgili olan değerlerden oluşan kayıttaki her değer kayıtın belirli bir alanına karşılık gelir ve birkaç byte yer tutar.
•Alanların isimleri onların karşılık geldiği tipler bir kayıt tipini ya da kayıt biçimi tanımını oluşturur. Bir veri tipi bir alanın alabileceği değeri belirler.
Veri tipleri
|
- integer |
} |
sayısal |
|
- sabit uzunluk |
} |
karakterler dizisi |
Kütükte kayıt yapıları
Bir kütük kayıtlardan oluşur ve kütük sabit uzunluklu kayıtlardan ya da değişken uzunluklu kayıtlardan oluşabilir.
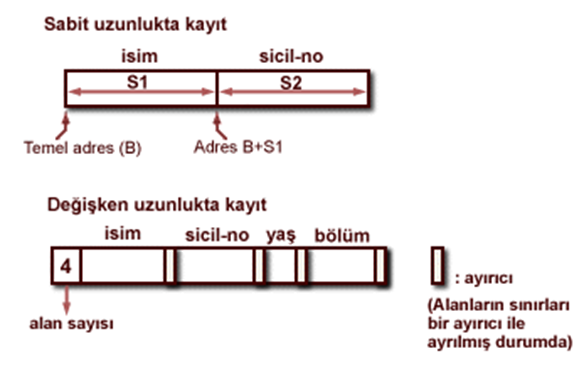
Değişken uzunluklu kayıtlar
Bir kütükte değişken uzunluklu kayıtların olması aşağıdaki nedenlerden dolayı gereklidir:
•değişken uzunluktaki alanların olması
•tekrarlanan alanların olması
•seçenekli alanların olması
•farklı kayıt tiplerinin (eğer farklı tiplerin ilgili kayıtları bir arada tutuluyorsa) olması
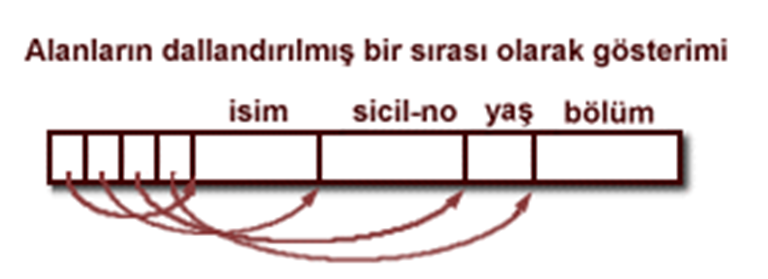
Kayıtların alternatif bir gösterimi
Blok (sayfa) Biçimi : Uzunluğu Sabit Kayıtlar
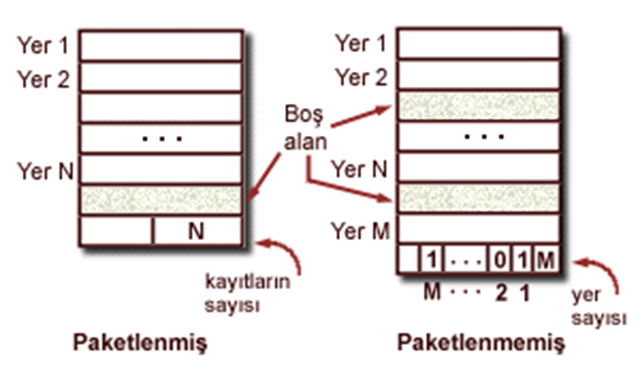
Kayıt_no(kno) = <sayfa_no, yer#>
Kayıtların yer değiştirmesi boş alan yönetimi için kno değişmesini gerektirir.
Sayfa Biçimi : Uzunluğu Değişken Kayıtlar
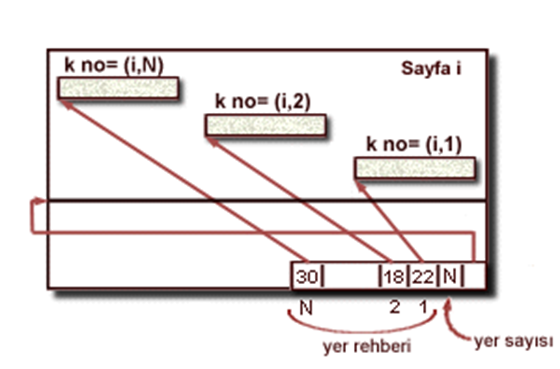
Uzunluğu değişken kayıtları sayfa içinde yer değiştirebiliriz (kno’yu değiştirmeden). Bundan dolayı sabit uzunluklu kayıtlara tercih edilebilirler.
Blokların kütükte organizasyonu

- Eğer kayıtların sayfa sınırlarını aşmalarına izin verilmiyorsa buna aktarımsız (unspanned)organizasyon denir.
- Eğer bir kayıt birden fazla bloğa taşınabiliyorsa buna aktarımlı (spanned) organizasyon denir.
Kütük blokları
•Ardısıra (contigious) atama: Kütük blokları diskteki ardısıra bloklara atanır. Bu tür kütüklerden okumak kolay ancak kütüğün genişlemesi zordur.
•Bağlantılı (linked) atama: Her kütük bloğu bir diğerine bağlanabilmek için bir göstergeye (pointer) sahiptir. Bu tür kütüklerin genişlemesi kolay ancak okuma işlemi yavaştır.
•Ardısıralı disk bloklarının salkımlarının (clusters) birbiriyle bağlanması.
•Dizinlenmiş (indexed) atama: Bir ya da daha fazla dizin blok gerçek kütük bloklarına işaret eden göstergeler içerirler. Bu yapıyla kayıtları niteliklerin değerini belirterek hızlı bir şekilde bulmak mümkündür.
Kayıtların Kütükleri
VTYS’nin yüksek seviyelerinde kayıtlar ve kayıtların kütükleri üzerinde operasyon gerçekleştirilir. Kütük, kayıtların bir grubundan oluşmuş sayfaların toplamıdır. Kütüklerle kayıtların giriş, silme, değiştirme, bir kayıdı okuma ve tüm kayıtların üzerinden geçme gibi operasyonları gerçekleştirilebilir.
Sıralanmamış (unordered) Kayıtların Kütüğü
•En basit kütük yapısıdır.
•Yeni kayıtlar kütüğün sonuna eklenir.
•Yeni kayıt eklemek çok hızlıdır.
•Kayıt arama operasyonu linear aramayı gerektirir.
•Kayıt silme işlemi yavaştır.
Sıralanmış (ordered) Kayıtların Kütüğü
Diskteki kütüğün kayıtları kayıttaki bir alanın değerine göre fiziksel olarak sıralanmıştır. Bu alana kütüğün sıralayan alanı (ordering field) denir. Ve bu tür kütüklere sıralanmış ya da sırasal (sequential) kütük adı verilir.
Bazı avantajları:
•Sıralayan alan değer sırasına göre kayıtların okunması oldukça hızlı
•Sıralayan alan değer sırasına göre bir sonraki kayıtın bulunması oldukça hızlı
•Sıralayan alan değer üzerinde bir arama kriterine göre kayıtların aranması oldukça hızlı
Bu tür kütüklerde kayıtların girme ve silme işlemi oldukça pahalıdır. Çünkü kayıtlar fiziksel olarak da sıralanmış olmak zorundadır. Bu işlemleri biraz hızlandırmak için bazı teknikler kullanılabilir:
–Silinmiş işareti kullanmak ve belli periyotlarla kütüğü organize etmek.
–Giriş için her blok içinde gelecek yeni kayıtlar için boş alan bırakmak.
–Geçici olarak bir sıralanmamış kütük (buna overflow ya da transaction kütük denir) yaratmak ve yeni kayıtları bu kütüğün sonuna eklemek. Daha sonra da bunu belli periyotlarla sıralı (master) kütükle birleştirmek.
Kütükteki boş alanların takibi
Kütükteki boş alanların takibi için en önemli iki yöntem:
•Liste Kütükler
•Sayfa Rehberli Kütükler
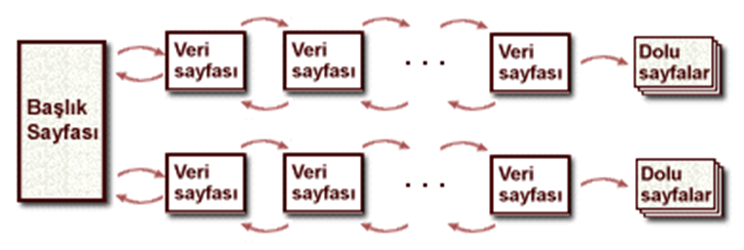
Liste Kütükler
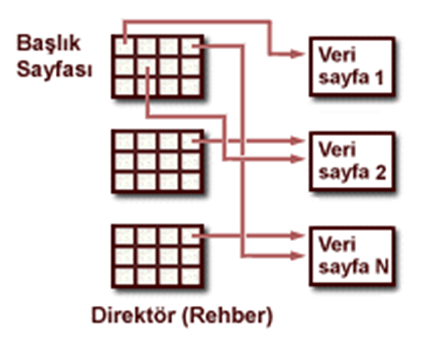
Sayfa rehberli kütükler
Sistem katalogları
Sistem kataloglarında aşağıdaki bilgiler tutulur :
•Her dizin için; dizinin yapısı (örneğin daha sonra göreceğimiz B+_ağacı) ve arama anahtarı alanları,
•Her ilişki için; ilişkinin ismi, kütük yapısı, niteliklerin isimleri ve tipleri, dizinlerin isimleri, tutarlılık kısıtları vs tutulur.
•Her görünüş için; görünüş ismi ve tanımı, istatistikler, yetki-verme, arabölge (buffer) büyüklüğü vs. tutulur.
•Kataloglar da ilişkiler gibi yapılanıp sistemde tutulurlar.
Kütük Organizasyonları
•Kütük organizasyonlarından Heap kütükleri bir kütükteki tüm kayıtların alınıp getirilmesi durumlarında uygun bir organizasyondur.
•Sıralanmış kütük organizasyonu ise kayıtların belli bir sırada alınıp getirilmesi durumunda ya da yalnızca bir aralıktaki kayıtların getirilmesinde çok etkili bir şekilde kullanılabilmektedirler.
•Dağıtılmış (hashed) kütük organizasyonları ise eşitliği gerektiren seçmelerde iyi sonuç vermektedirler.
Dağıtım (Hashing) Teknikleri
Bu tekniklerde anafikir şudur: Kütük kovalardan (bucket) oluşur ve kova, birincil sayfa artı sıfır ya da daha fazla ek sayfadan oluşur. Bir h dağıtım fonksiyonu vardır ve bunu kayıttaki dağıtım alan değerine uyguladığımızda kayıtın diskte depolandığı disk blokunun (kovanın) adresini verir. Yani h fonksiyonu dağıtım (hash) uygulanan alanı adres alanına dönüştürür.
Örnek olarak bilinen bir dağıtım fonksiyonu :
h(K) = K mod M ‘dir.
Burada K dağıtım alan değeridir ve arama alanı olarak da bilinir. Seçilmiş M ise bir tam sayı değeridir ve genellikle adres alanının büyüklüğüne eşittir.
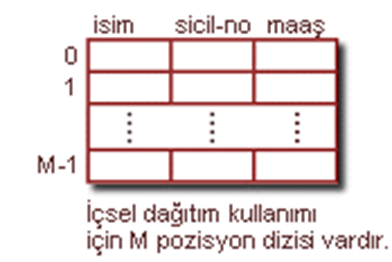
•Dağıtım fonksiyonu h : h(r) = r kaydının bulundugu kovanın adresini verir. Her zaman farklı alan değerlerini farklı adres alan değerlerine dönüştüren bir dağıtım fonksiyonu bulmak zordur. Bundan dolayı çakışma (collision) meydana gelir ve bu durumlarda aşağıdaki tekniklerden birisi ya da birkacinin kombinasyonu kullanılabilir:
•Açık adresleme (open addressing) : Dolu olmayan bir adres bulana kadar bir sonraki adresi kontrol etmek suretiyle çalışır.
•Zincirleme (chaining) : Yeni kayıtı boş bir alana yerleştirir ve dolu alandan bu adres alanına ulaşabilmek için bir göstergeyi dolu olan alana ilave eder.
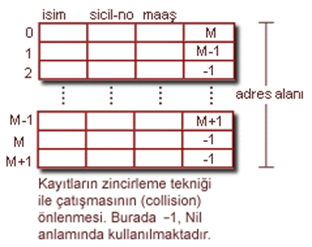
• Çoklu dağıtım (multiple hashing) : Burada iki dağıtım fonksiyonu söz konusudur. Öncelikle birincisi uygulanır. Eğer çakışma olursa ikinci fonksiyon uygulanır.
Dışsal (External) Dağıtım
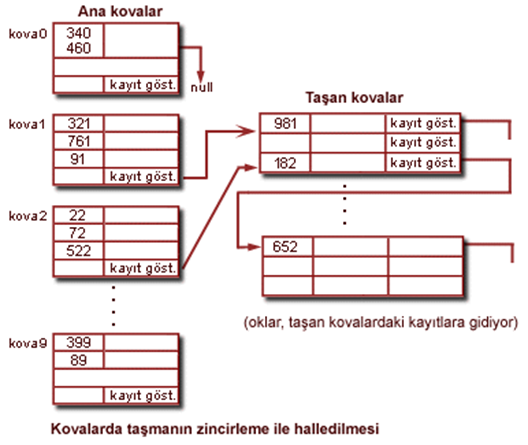
İyi bir dağıtım fonksiyonunun amacı adres alanı üzerinde kayıtları mümkün olduğu kadar düzgün (uniform) olarak dağıtmak, çakışmayı minimize etmek ve çok kullanılmamış alan bırakmamaktır.
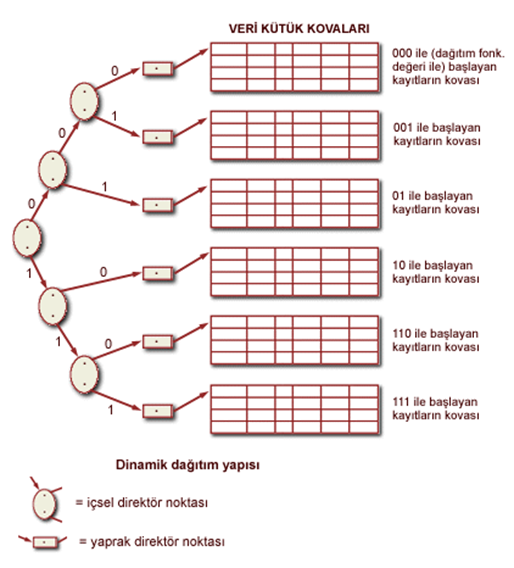
Dinamik Dağıtım Yapısı
Bu yapıda direktör bir ağaç yapısına benzer ve dapıtım fonksiyonunun sonunda elde edilen dağıtılmış ikili veri (binary string) kullanılarak aranan kayıdın hangi kovada olduğu tespit edilir.
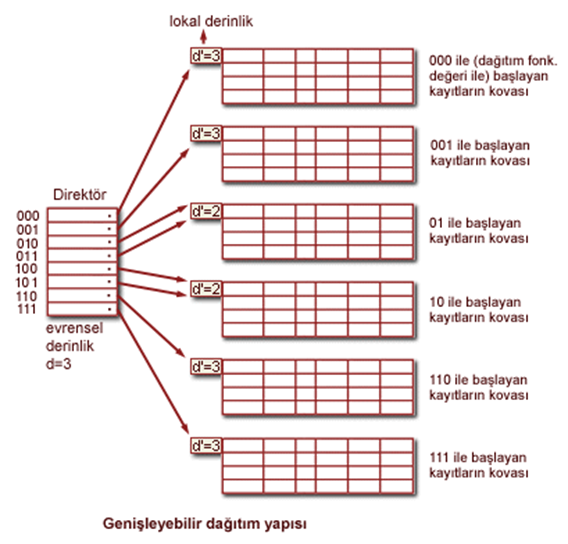
Genişleyebilir Dağıtım Yapısı
Bu yapıda dinamik dağıtım yapısı gibi bir ağaç şeklindeki direktör yerine düz bir direktör kullanır. Aynı şekilde, aranan kayıdın hangi kovada olduğu dağıtım fonksiyonunun sonucunda elde edilen ikili değere göre bulunur.
Dizinleme (Indexing)
Bir kütükte dizinleme arama anahtar alanı üzerinden seçme işleminin hızlandırılmasını sağlar. Bir ilişkideki niteliklerin herhangi bir alt kümesi bir dizin için arama anahtarı olabilir. Arama anahtarı bir ilişkideki anahtar nitelikle aynı şey değildir. Bir dizin verilerin bir grubunu içerir ve bütün verilerin etkin bir şekilde alınıp getirilmesini sağlar.
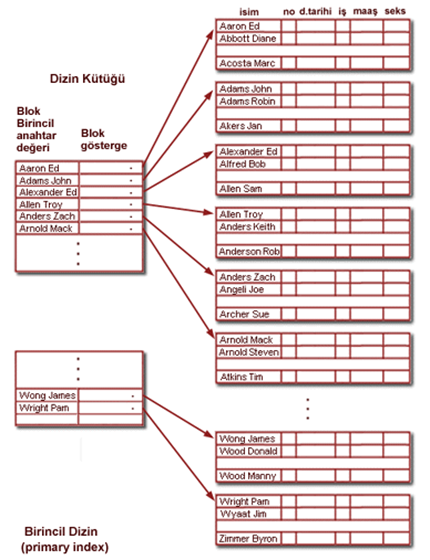
Birincil dizin yapısı
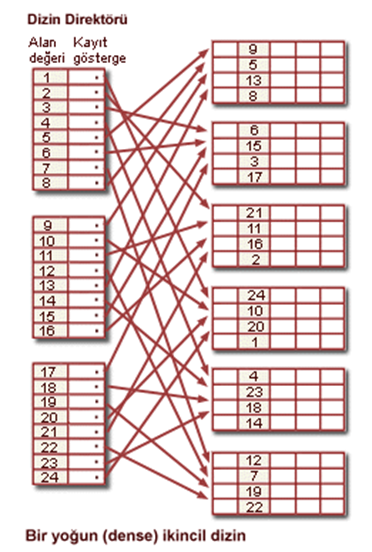
İkincil dizin yapısı
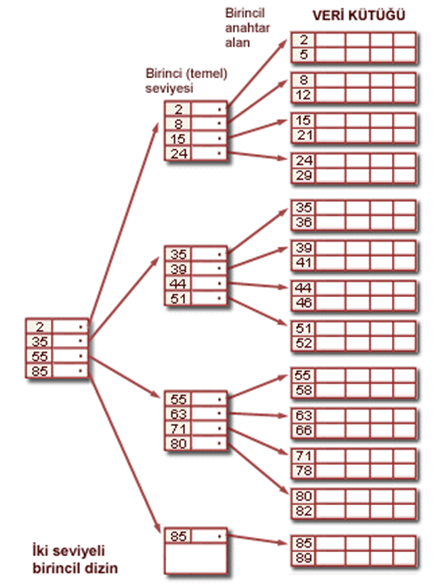
İki seviyeli birincil dizinin yapısı
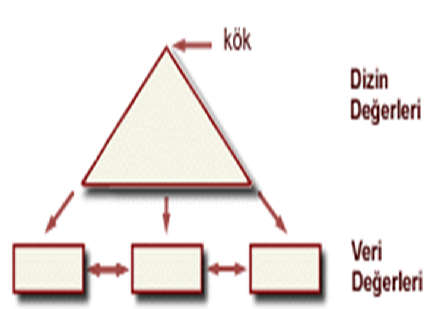
B+ Ağaç Yapısı
•En fazla kullanılan dizin yapısı
•F : bir düğümün (node) olabilecek en fazla alt dügüm sayısı
•N : yaprak sayfalarının sayısı
•Bu ağaç her durumda dengelidir
•Kök hariç %50 doluluk oranı tutturulur
•Eşitlik ve aralık tabanlı aramaları etkin bir şekilde destekler
•Arama kökten başlar ve anahtar karşılaştırmaları ile yapraklara kadar iner.
B+ Ağaç yapısının genel görünümü
Örnek B+ Ağacı
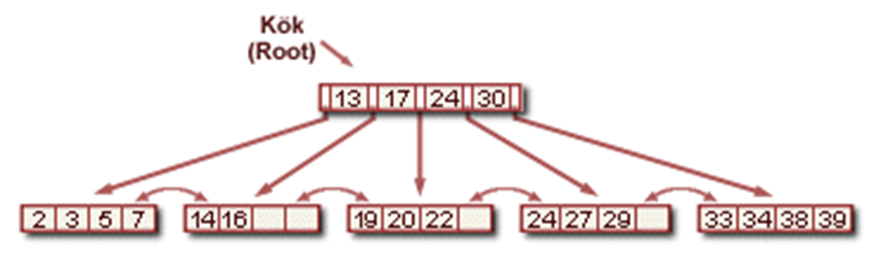
B+ Ağaç Veri Yapısında Bir Verinin Girişi
•doğru yaprak L’yi bul
•veriyi L’ye koy
•Eğer L’de yeterli boşluk varsa, bitti!
•Aksi halde L’yi, L ve L2 olarak ikiye ayır
–L’deki verileri eşit bir şekilde tekrar dağıt ve orta anahtarı yukarıya kopyala
–Dizinde L2’yi L’nin ailesine bağla
•Bu içsel döngülerle yapılabilir. Bölme ağacın büyümesine neden olur. Kökte bölünme ağacın yüksekliğinin artmasıyla sonuçlanır. Yani ağaç ya genişler ya da bir seviye yükselir.
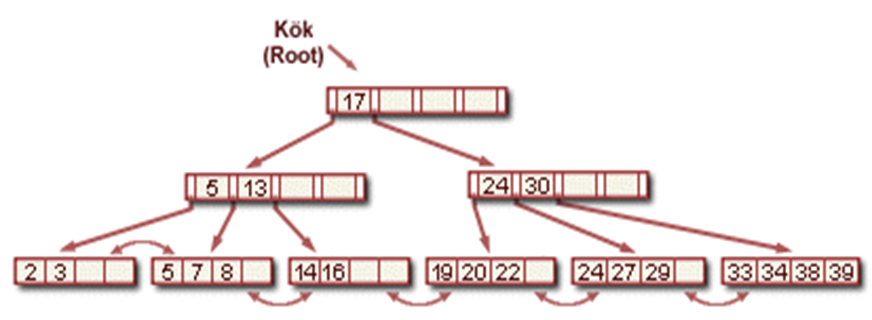
Örnek (Ekleme)
Eğer biraz önceki B+ ağaç örneğine 8 verisinin girişini yaparsak aşagıdaki B+ ağaç yapısını elde ederiz.
Verilerin B+ Ağacından Silinmesi
•Kökten başla ve verinin dahil olduğu L yaprağını bul
•Veriyi sil
•Eğer L en az %50 dolu ise, bitti!
•Aksi takdirde
–Komşu düğümlerden ödünç alıp tekrar dağıtım yapılması denenir.
–Eğer tekrar dağıtım başarısız olursa L’yi komşuları ile birleştir.
•Eğer bir birleştirme olursa, L’nin ailesinden bir çıkışı silme durumu oluşur ve köke kadar çıkma durumu olabilir ve ağacın yüksekliğinin azalmasıyla sonuçlanabilir.
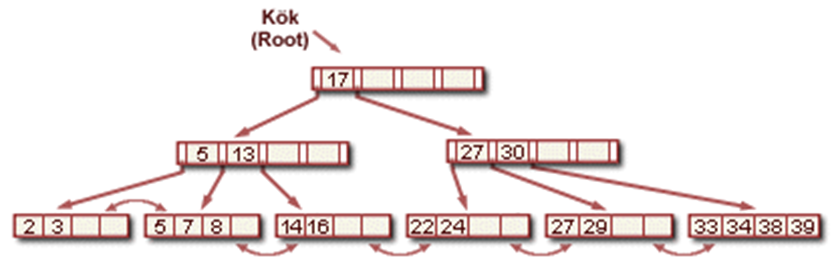
Örnek (Silme)
•Bir önceki B+ ağacından ( 8’in girişi yapıldıktan sonraki hali), sırayla 19, 20 ve 24’ü silelim.
•19’u silmek kolay
•20’yi silmek tekrar dağıtımın yapılması ile bitirilebilir.
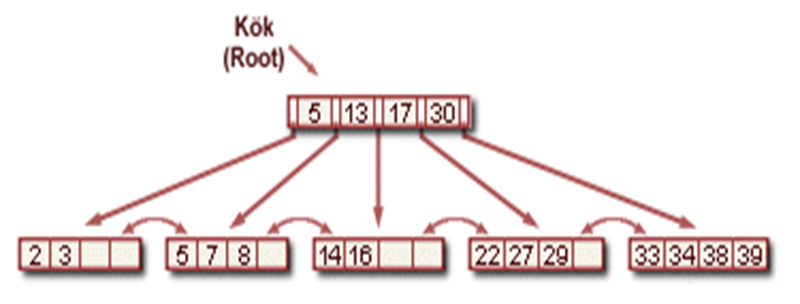
•24’ün silinmesi birleştirme işlemini sorunlu kılıyor.
•19 ve 20’nin silinmesinden sonraki B+ ağacı :
•24’ün silinmesi sonucundaki B+ ağacı :
Etiketler : Fiziksel veritabanı nedir
- İzzet A.
- 26.04.2019 10:47:28
- 14 Yorum
- 5613 Okunma
Henüz yorum yapılmamış ilk yorumu siz yapabilirsiniz.
-
En Çok Okunanlar
-
 Asp.net Mvc ile Dosya yükleme "File Upload" işlemi nasıl Yapılır
Asp.net Mvc ile Dosya yükleme "File Upload" işlemi nasıl Yapılır -
 Veritabanı tasarım safhalarında gösterildiği gibi ihtiyaçlar analizini takip eder ve veritabanında tutulacak olan verilerin yüksek seviyede bir gösterimini verir.
Veritabanı tasarım safhalarında gösterildiği gibi ihtiyaçlar analizini takip eder ve veritabanında tutulacak olan verilerin yüksek seviyede bir gösterimini verir. -
İlişkisel cebir (Relational Algebra) biçimsel bir sorgu dili olarak tanımlanabilir.
-
 ingilzcede alfabeler ve kalimelerin okunuşları ve kuralları
ingilzcede alfabeler ve kalimelerin okunuşları ve kuralları -
 c# ile her bilgisayarda çalışacak dosya yolu tanımlama
c# ile her bilgisayarda çalışacak dosya yolu tanımlama
-
Yeni Yüklenenler
-
C# textbox autocomplete "otomatik tamamlama" textbox a girilen değirin otomatik tamamlaması
-
İlişkisel cebir (Relational Algebra) biçimsel bir sorgu dili olarak tanımlanabilir.
-
Fiziksel veritabanı nedir? Fiziksel veritabanı fiziksel tasarımının mantıksal yapısı.
-
Veritabanı tasarım safhalarında gösterildiği gibi ihtiyaçlar analizini takip eder ve veritabanında tutulacak olan verilerin yüksek seviyede bir gösterimini verir.
-
Veritabanlarının mimari yapıları ve özellikleri.